Architektur-Review
Wir prüfen bestehende Cluster, geplante Hardware, Netzwerkdesign, Storage, Backups, Monitoring und Betriebsabläufe. Danach ist klar, welche Risiken real sind und welche Baustellen nur schön auf Folien aussehen.
Proxmox VE ist stark, wenn Architektur, Netzwerk, Storage, Backups und Betrieb zusammenpassen. Genau dort helfen wir: beim Review bestehender Cluster, beim Neubau, bei VMware-Migrationen, bei Ceph- oder 3-Tier-Designs und bei den Abläufen, die nach der Installation über Stabilität entscheiden.
Die meiste Arbeit erledigen wir remote. Für Planung, Troubleshooting, Workshops, Automatisierung und Betriebsbegleitung braucht es keinen Vor-Ort-Termin, sondern sauberen Zugriff, klare Zuständigkeiten und jemanden, der die Risiken im Setup erkennt.
Wir prüfen bestehende Cluster, geplante Hardware, Netzwerkdesign, Storage, Backups, Monitoring und Betriebsabläufe. Danach ist klar, welche Risiken real sind und welche Baustellen nur schön auf Folien aussehen.
Wir planen neue Proxmox-Umgebungen oder räumen gewachsene Setups auf. Dazu gehören Node-Sizing, Netztrennung, Storage-Entscheidung, PBS, Zugriffskonzepte, Dokumentation und ein realistischer Migrationspfad.
Updates, Reboots, Ceph-Recovery, Firmware, Kapazitätsplanung und Restore-Tests brauchen einen Ablauf. Wir helfen, daraus Routine zu machen, statt jedes Wartungsfenster neu zu erfinden.
Ein brauchbares Review braucht Logs, Netzwerkpläne, Zugriff auf Hosts, Storage und Monitoring sowie Zeit für die richtigen Fragen. Das funktioniert remote meistens besser als ein Tag im Serverraum. Wenn physische Arbeiten nötig sind, binden wir dein Team, Smart Hands oder vorhandene Dienstleister ein.
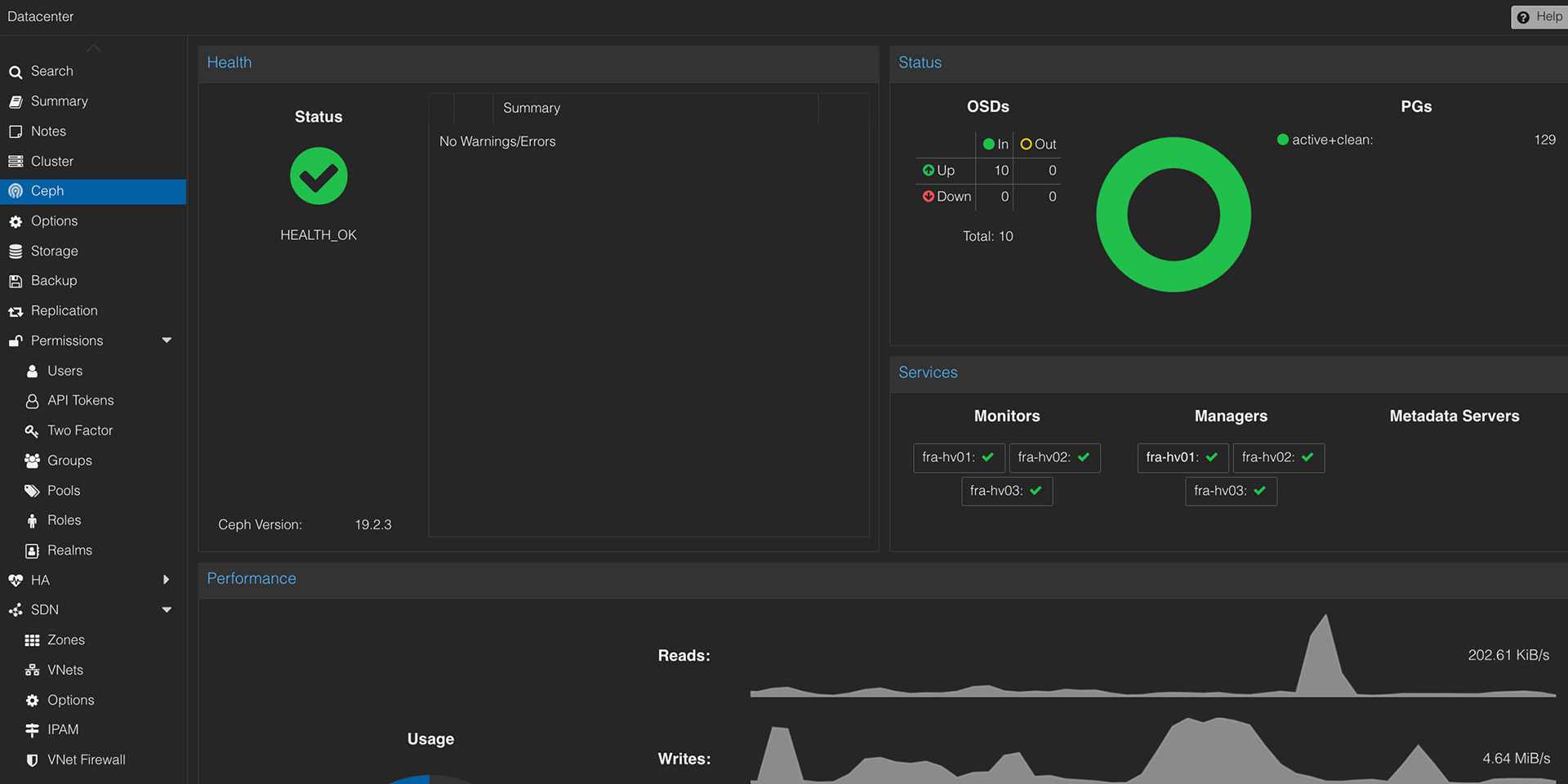
Wir klären Ziele, Ist-Zustand, Hardware, Netzwerk, Storage, Ausfalltoleranz, Backup-Stand und Verantwortlichkeiten.
Wir prüfen PVE, PBS, Ceph, ZFS, Netzwerk, HA, Firmware, Monitoring, Logs und typische Betriebsrisiken.
Du bekommst keine Tool-Liste, sondern konkrete nächste Schritte: was bleiben kann, was geändert werden sollte und was warten darf.
Wir setzen selbst um, begleiten dein Team oder liefern Runbooks und Reviews für kritische Schritte wie Migration, Update oder Storage-Umbau.
Quorum, Corosync, Management-Netz, VLANs, Bonding, HA-Gruppen, Wartungsfenster und klare Betriebsgrenzen. Ein Proxmox-Cluster ist erst dann gut geplant, wenn auch der Ausfall eines Nodes langweilig bleibt.
Mehr zur PlanungCeph kann stark sein, wenn Netzwerk, OSD-Design, Recovery-Verhalten und Kapazitätsplanung stimmen. Wir prüfen, ob Ceph wirklich passt, oder ob ZFS, NFS, iSCSI oder externer Storage die bessere Wahl ist.
Mehr zu CephBestandsaufnahme, VM-Konvertierung, Netzwerk-Mapping, Testmigration, Cutover und Fallback. Weg von VMware heißt nicht: alles an einem Wochenende kopieren und hoffen.
Mehr zur MigrationDatastores, Retention, Prune, Garbage Collection, Verschlüsselung, Offsite-Sync und Restore-Tests. Ein Backup-Konzept zählt erst, wenn ein Restore unter realistischen Bedingungen funktioniert.
Mehr zu PBSAPI-Tokens, Ansible, OpenTofu/Terraform, Packer, Templates, cloud-init und Git-basierte Provisionierung. Automatisierung soll Betrieb einfacher machen, nicht nur YAML produzieren.
Mehr zur AutomatisierungPVE-, PBS- und Ceph-Health, Firmware, Kernel-Updates, Alerting, Kapazitätstrends und Runbooks. Wir bauen Checks so, dass sie im Alltag helfen und nicht nur rote Dashboards erzeugen.
Mehr zu BetriebCompute-Cluster mit externem Shared Storage, SAN-Design, IBM FlashSystem, Policy Based HA und klare Verantwortlichkeiten zwischen Host, Netzwerk und Storage.
Mehr zu 3-TierDM Multipath, ALUA, WWIDs, Pfadredundanz, Controller-Failover, Switch-Wartung und Monitoring. Multipath muss getestet werden, nicht nur in der Doku stehen.
Mehr zu MultipathRemote-Workshops für Admin-Teams: Architektur-Review, UI-Durchgang, HA, Backup/Restore, Storage, Updates und typische Fehler aus echten Setups.
Mehr zu WorkshopsBeratung darf nicht bei "könnte man mal" enden. Je nach Projekt liefern wir Review, Plan, Umsetzung, Runbook oder Betriebsbegleitung. Wichtig ist, dass dein Team danach besser entscheiden und ruhiger betreiben kann.
Architektur- und Risiko-Review für bestehende PVE-Cluster
Netzwerkplan für Management, Corosync, Storage, VM-Traffic und Backup
Storage-Entscheidung: Ceph, ZFS, NFS, iSCSI, Fibre Channel oder externer Shared Storage
Backup- und Restore-Konzept mit Proxmox Backup Server
Migrationsplan für VMware, Hyper-V, einzelne KVM-Hosts oder alte Proxmox-Setups
Runbooks für Updates, Reboots, Node-Ausfall, Storage-Störung und Restore
Monitoring-Konzept für PVE, PBS, Ceph, Hardware, Netzwerk und Kapazität
Automatisierung mit API, Ansible, OpenTofu/Terraform, Templates und cloud-init
In den meisten Fällen nicht. Architektur, Review, Migration, Monitoring, Automatisierung und Workshops funktionieren sauber remote per VPN, Screensharing, SSH, Out-of-band-Konsole und gemeinsamem Runbook. Vor Ort ist nur dann sinnvoll, wenn wirklich Hardware, Verkabelung oder Rechenzentrumszugang der Engpass ist.
Nein. Ceph ist gut, wenn genügend Nodes, Netzwerkbandbreite, OSDs und Betriebswissen vorhanden sind. Für kleinere Umgebungen können ZFS, PBS, NFS, iSCSI oder ein sauber angebundener Shared Storage wirtschaftlicher und ruhiger sein.
Ja. Ein Review ist oft der bessere Einstieg. Wir schauen auf reale Risiken, nicht auf Geschmack. Wenn ein Setup stabil ist, aber nur Dokumentation, Monitoring oder Backup-Tests fehlen, sagen wir das auch so.
Ja. Wichtig sind Inventarisierung, Abhängigkeiten, Netzwerk-Mapping, Testmigrationen und ein Fallback. Die eigentliche VM-Konvertierung ist nur ein Teil des Projekts.
Für Unternehmen, IT-Teams, Hoster und MSPs, die Proxmox produktiv betreiben wollen oder bereits betreiben. Typische Auslöser sind VMware-Kosten, wachsende Cluster, unsichere Backups, fehlendes Monitoring oder Storage-Fragen.
Ob Neubau, VMware-Migration oder Optimierung eines bestehenden Clusters: wir starten remote, prüfen nüchtern und liefern eine Empfehlung, mit der dein Team arbeiten kann.
Proxmox-Projekt besprechen