Ceph macht Proxmox stark, wenn das Design stimmt.
Ceph ist kein magischer Shared Storage. Es ist ein verteiltes Storage-System, das sauber geplante Hardware, Netzwerke, Failure Domains und Betriebsprozesse braucht. Wir helfen bei Proxmox-Ceph-Clustern, die Performance liefern, Ausfälle sauber abfangen und deren Recovery-Verhalten verstanden ist.
OSD- und Geräte-Design
Wir planen OSD-Anzahl, Device Classes, NVMe-, SSD- und HDD-Rollen, DB/WAL-Platzierung und sinnvolle Reservekapazität. Dabei zählt nicht nur die Rohkapazität, sondern auch IOPS, Latenz und Recovery-Zeit.
Netzwerktrennung
Ceph public und cluster network brauchen genug Bandbreite und klare Pfade. Wir bewerten 10G, 25G oder mehr, MTU, Bonding, Switch-Redundanz und die Frage, ob Live-Migration und Backups dieselben Links belasten.
CRUSH und Failure Domains
CRUSH entscheidet, wo Daten landen. Wir modellieren Hosts, Racks, Räume oder Standorte passend zur realen Infrastruktur und vermeiden Policies, die auf dem Papier redundant wirken, aber denselben Fehlerbereich treffen.
Replikation und Erasure Coding
Replica 3 ist nicht automatisch die beste Antwort. Wir bewerten Workload, Performance, Kapazitätsdruck und Wiederherstellungszeiten und entscheiden, wo Replikation oder Erasure Coding sinnvoll ist.
Recovery-Verhalten
Ein Ceph-Cluster muss auch während Recovery bedienbar bleiben. Wir justieren Recovery-Parameter, beobachten Backfill, Scrubbing und Rebalancing und verhindern, dass ein Hardware-Ausfall den produktiven Storage überlastet.
Kapazitätsplanung
Nearfull ist kein Betriebszustand. Wir planen nutzbare Kapazität, Wachstum, Alerting, Austauschzyklen und Schwellenwerte, damit Erweiterungen nicht erst starten, wenn der Cluster bereits unter Druck steht.
Ceph-Fragen, die über Stabilität entscheiden
Passen Hardware und Netzwerk wirklich zu Ceph?
Zu wenige OSDs, langsame Links oder gemischte Geräte ohne Konzept führen schnell zu Latenzproblemen. Wir prüfen die Grundlage, bevor Daten produktiv auf den Cluster wandern.
Was passiert beim Ausfall eines Hosts?
Recovery ist nicht nur ein Haken im Dashboard. Wichtig ist, wie lange der Cluster degradiert läuft, welche Performance bleibt und ob genug Reserve für Backfill vorhanden ist.
Welche Pools brauchen welche Eigenschaften?
VM-Disks, ISO-Storage, Backups und Archivdaten haben unterschiedliche Anforderungen. Wir trennen Pools, Regeln und Replikationsfaktoren nach realem Nutzungsprofil.
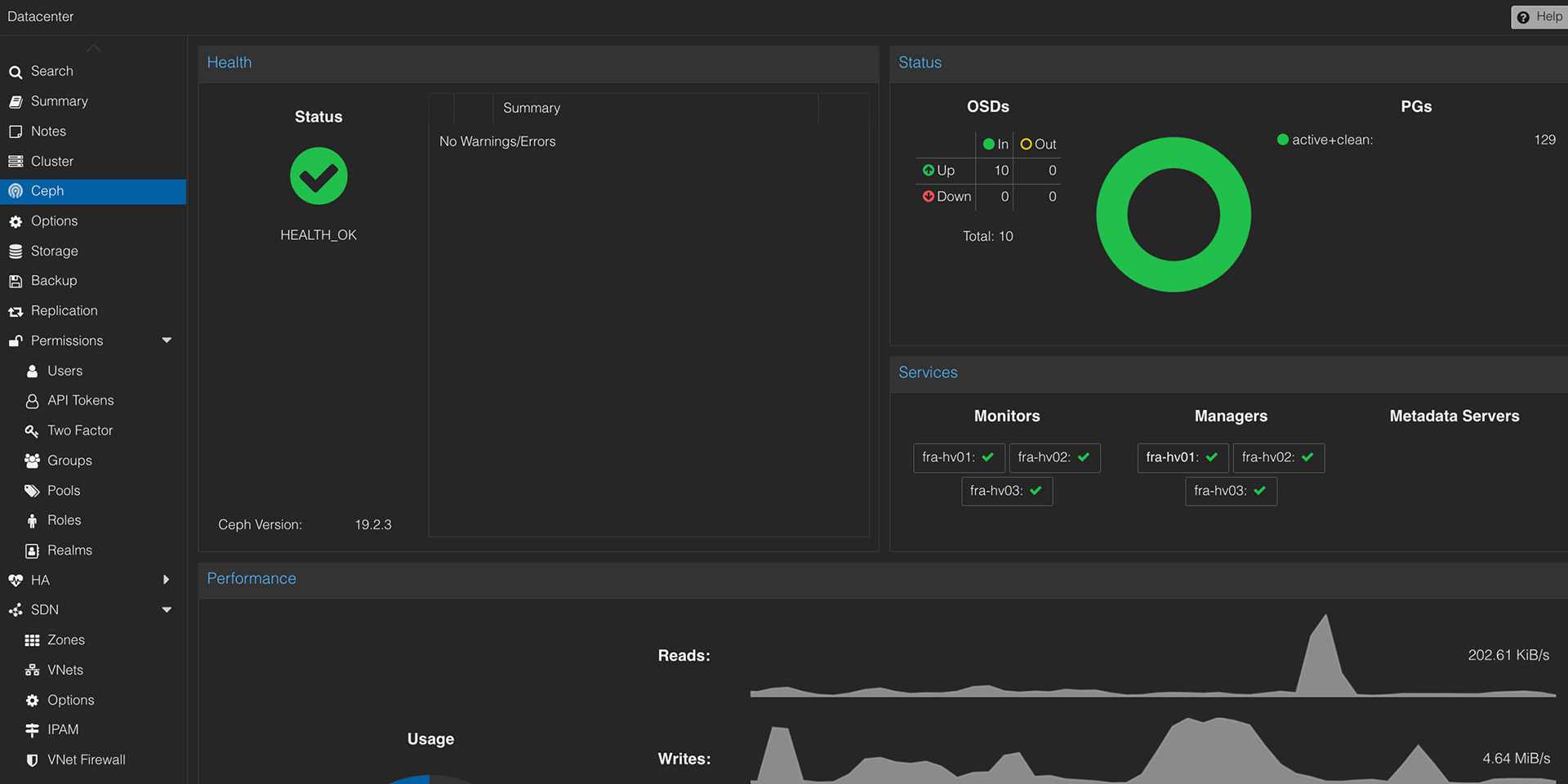
Wie wird Ceph überwacht?
Ceph HEALTH_WARN alleine reicht nicht. OSD-Latenz, PG-Zustände, Scrubbing, Full Ratios, Netzwerkfehler und Kapazitätstrends müssen sichtbar sein.
Ceph planbar einführen oder stabilisieren
Review oder Zielbild
Wir analysieren bestehende Ceph-Cluster oder planen ein neues Setup anhand von Workloads, Hardware und Verfügbarkeitszielen.
Storage-Design
Wir definieren OSD-Layout, Netz, CRUSH-Regeln, Pools, Replikation, Recovery-Parameter und Monitoring-Punkte.
Aufbau und Tests
Wir bauen das Setup, testen Latenz, Durchsatz, Host-Ausfall, Rebalancing und Restore-Szenarien.
Betrieb und Optimierung
Wir begleiten Erweiterungen, Performance-Analysen, OSD-Tausch, Updates und Kapazitätsplanung.
Technologien
Weitere Detailseiten
Cluster-Planung
Quorum, Corosync, Netzwerk, HA und Betriebsmodell.
VMware-Migration
Bestandsaufnahme, Testmigration, Cutover und Fallback.
Proxmox Backup Server
Datastores, Retention, Offsite-Sync und Restore-Tests.
Automatisierung
API, Ansible, OpenTofu, Templates und cloud-init.
Monitoring & Wartung
Health Checks, Updates, Firmware und Kapazitätstrends.
3-Tier Architekturen
Compute, SAN, Shared Storage und klare Betriebsgrenzen.
Multipath-Architekturen
Fibre Channel, iSCSI, ALUA, multipathd und Failover-Tests.
Proxmox Workshops
Beratung, UI-Durchgang, Betriebspraxis und Team-Enablement.
Ceph-Cluster prüfen oder neu planen?
Wir schauen auf Hardware, Netz, Pools und Recovery-Verhalten und sagen dir, ob dein Storage-Konzept tragfähig ist.
Proxmox-Projekt besprechen