Ein Proxmox-Cluster braucht laufende Pflege, nicht nur ein Dashboard.
PVE, PBS und Ceph zeigen viele Zustände an, aber daraus entsteht noch kein belastbarer Betrieb. Wir bauen Monitoring, Wartungsprozesse und Update-Abläufe so auf, dass Probleme früh sichtbar werden und Änderungen kontrolliert passieren. Das Ziel ist weniger Alarmrauschen und mehr klare Signale.
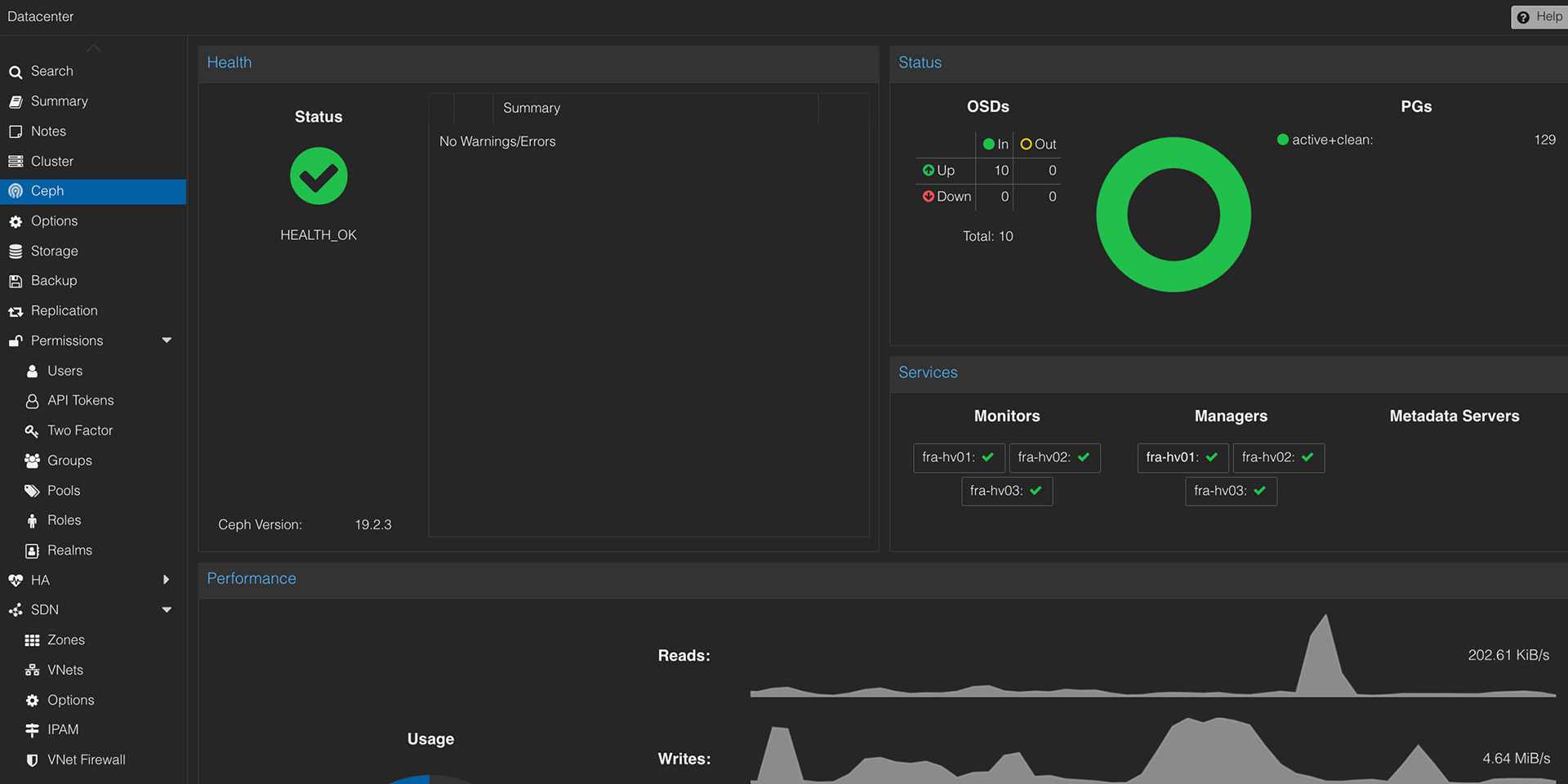
PVE-, PBS- und Ceph-Health
Wir überwachen Cluster-Status, Node-Verfügbarkeit, HA-Zustände, Storage, Backup-Jobs, PBS-Verify-Jobs, Ceph HEALTH und kritische Systemdienste.
Metriken und Dashboards
CPU, RAM, Disk, I/O, Netzwerk, OSD-Latenz, PG-Zustände, Datastore-Auslastung und VM-Ressourcen werden so aufbereitet, dass Trends und Engpässe sichtbar werden.
Alerting und Eskalation
Nicht jeder Warnhinweis muss jemanden wecken. Wir trennen Info, Warnung und kritische Alarme, definieren Eskalationswege und vermeiden Alarmmüdigkeit.
Update-Strategie
Proxmox-, Kernel-, Ceph- und PBS-Updates brauchen Reihenfolge, Checks und Wartungsfenster. Wir planen Updates so, dass Cluster-Health, HA und Backups vor und nach jedem Schritt geprüft werden.
Firmware und Hardware
Storage-Controller, NICs, BIOS, BMC, SSD-Firmware, SMART-Werte und Redfish/IPMI gehören zum Betrieb. Wir nehmen Hardware-Zustände ins Monitoring und in Wartungspläne auf.
Kapazitätstrends
Cluster laufen selten plötzlich voll. Die Warnzeichen sind vorher da: RAM-Druck, OSD-Auslastung, Backup-Wachstum, IOPS-Limits oder Netzwerkspitzen. Wir machen diese Trends sichtbar.
Monitoring-Fragen für den Alltag
Welche Alarme sind wirklich kritisch?
Ein einzelnes Dashboard löst noch kein Problem. Wir definieren, welche Zustände sofortige Reaktion brauchen und welche in die nächste Wartung gehören.
Wer reagiert außerhalb der Bürozeit?
Monitoring ohne Zuständigkeit bleibt Dekoration. Wir klären Kontaktwege, Eskalation, Reaktionszeiten und welche Informationen in einem Alarm stehen müssen.
Wie werden Updates geprüft?
Vor Updates müssen Backups, HA, Ceph, freie Kapazität und bekannte Release-Hinweise geprüft werden. Danach zählen Health Checks und ein klarer Abbruchpunkt.
Wann wird Kapazität erweitert?
Neue Hosts, Disks oder Netzwerk-Upgrades brauchen Vorlauf. Wir definieren Schwellenwerte, ab denen Beschaffung und Planung starten.
Betrieb, der nicht erst im Ausfall beginnt
Ist-Zustand prüfen
Wir erfassen bestehende Checks, Dashboards, Alarme, Update-Stände, Firmware, Backups und bekannte wiederkehrende Probleme.
Signale definieren
Wir legen fest, welche Metriken, Logs und Health Checks wirklich relevant sind und welche Schwellenwerte dazu passen.
Monitoring einrichten
Checks, Dashboards, Alarmwege und Wartungsfenster werden eingerichtet und mit echten Fehlerszenarien geprüft.
Wartung etablieren
Wir dokumentieren Update-Abläufe, Firmware-Prüfungen, Kapazitätsreviews und regelmäßige Restore- oder Failover-Tests.
Technologien
Weitere Detailseiten
Cluster-Planung
Quorum, Corosync, Netzwerk, HA und Betriebsmodell.
Ceph-Storage
OSD-Design, CRUSH, Recovery-Verhalten und Kapazität.
VMware-Migration
Bestandsaufnahme, Testmigration, Cutover und Fallback.
Proxmox Backup Server
Datastores, Retention, Offsite-Sync und Restore-Tests.
Automatisierung
API, Ansible, OpenTofu, Templates und cloud-init.
3-Tier Architekturen
Compute, SAN, Shared Storage und klare Betriebsgrenzen.
Multipath-Architekturen
Fibre Channel, iSCSI, ALUA, multipathd und Failover-Tests.
Proxmox Workshops
Beratung, UI-Durchgang, Betriebspraxis und Team-Enablement.
Proxmox-Betrieb stabilisieren?
Wir prüfen Monitoring, Wartung und Update-Prozesse und bauen daraus einen Betrieb, der Probleme früher zeigt.
Proxmox-Projekt besprechen