Ein Proxmox-Cluster muss vor dem ersten Node geplant werden.
Ein stabiler Proxmox-Cluster entsteht nicht durch drei installierte Hosts und ein paar HA-Haken. Entscheidend sind Quorum, Netzwerk, Storage, Wartungsmodell und ein Betriebsplan, der auch beim Ausfall eines Switches oder Nodes noch funktioniert. Wir planen Proxmox-Cluster so, dass sie im Alltag wartbar bleiben und nicht erst im Incident verstanden werden.
Node- und Quorum-Design
Wir klären, ob drei Nodes reichen, ob ein QDevice sinnvoll ist und welche Failure Domains realistisch sind. Ziel ist ein Cluster, der keinen Split-Brain provoziert und bei Wartung oder Hardware-Ausfall vorhersehbar reagiert.
Corosync und Management
Corosync braucht ein sauberes, latenzarmes Netz. Wir planen getrennte Management-, Corosync- und Migrationspfade, prüfen MTU, Bonding, LACP und Switch-Redundanz und dokumentieren, welche Verbindung wofür gedacht ist.
VM-, Storage- und Backup-Netze
VM-Traffic, Storage-Replikation, Live-Migration und Backups gehören nicht ungeplant auf dieselbe Strecke. Wir trennen VLANs, definieren Uplinks und vermeiden Engpässe, die später jede Migration oder jeden Restore ausbremsen.
HA-Gruppen und Wartung
HA ist nur dann hilfreich, wenn Ressourcen, Prioritäten und Wartungsfenster sauber definiert sind. Wir planen HA-Gruppen, Failover-Reihenfolgen und Kapazitätsreserven, damit geplante Wartung nicht wie ein Ausfall behandelt wird.
Sizing und Hardware-Rollen
CPU, RAM, NVMe, Netzwerk und Remote Management müssen zum Workload passen. Wir bewerten, ob Nodes homogen sein sollten, welche Rolle Backup- oder Witness-Systeme haben und wo bewusst Reserven eingeplant werden müssen.
Betriebsdokumentation
Ein Cluster ohne Doku ist im Ernstfall teuer. Wir halten IP-Plan, VLANs, Storage-Entscheidungen, Wartungsabläufe, Restore-Pfade und Verantwortlichkeiten so fest, dass dein Team später nicht aus der Historie raten muss.
Fragen, die vor dem Aufbau geklärt sein müssen
Was passiert beim Ausfall eines Switches?
Ein Cluster sollte nicht nur einzelne Host-Ausfälle überleben. Wir prüfen, ob Corosync, Storage, VM-Traffic und Management auch bei Switch-, Link- oder Uplink-Ausfällen sauber weiterlaufen.
Welche Workloads dürfen live migrieren?
Nicht jede VM verhält sich gleich. Datenbanken, Storage-intensive Systeme und latenzkritische Dienste brauchen andere Regeln als kleine Webserver oder Testsysteme.
Wie laufen Updates und Reboots ab?
Kernel-Updates, Firmware, Proxmox-Releases und Ceph-Wartung brauchen einen Ablauf. Wir definieren Reihenfolge, Checks, Fallback und die Bedingungen, unter denen ein Node wieder produktiv genutzt wird.
Wo ist der geprüfte Restore-Pfad?
HA ersetzt kein Backup. Schon in der Cluster-Planung muss klar sein, wie VMs, Container, Konfigurationen und kritische Daten wiederhergestellt werden.
Vom Zielbild zum produktiven Cluster
Bestand und Anforderungen
Wir sammeln Workloads, Verfügbarkeitsziele, Netzwerk, Hardware, Storage, Backup-Ziele und interne Betriebsprozesse.
Architektur und Migrationsplan
Wir liefern ein Zielbild für Nodes, Netze, Storage, HA, Backup und Wartung inklusive klarer Umsetzungsschritte.
Aufbau und Validierung
Installation, Cluster-Join, Netztests, HA-Tests, Migrationstests und Restore-Proben werden vor der Übergabe geprüft.
Übergabe und Betrieb
Am Ende stehen Doku, Runbooks, Monitoring-Punkte und ein realistischer Update- und Wartungsprozess.
Technologien
Weitere Detailseiten
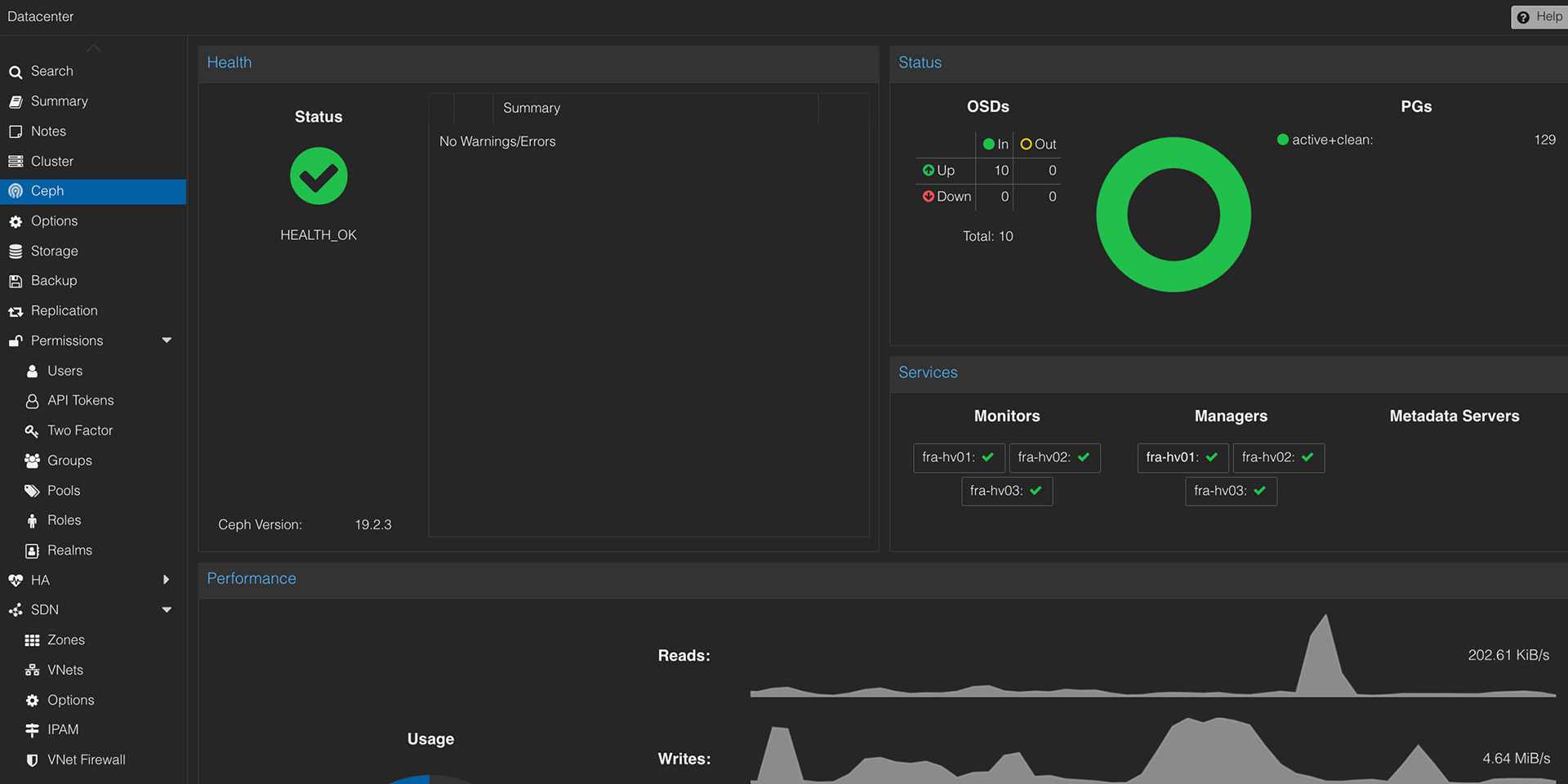
Ceph-Storage
OSD-Design, CRUSH, Recovery-Verhalten und Kapazität.
VMware-Migration
Bestandsaufnahme, Testmigration, Cutover und Fallback.
Proxmox Backup Server
Datastores, Retention, Offsite-Sync und Restore-Tests.
Automatisierung
API, Ansible, OpenTofu, Templates und cloud-init.
Monitoring & Wartung
Health Checks, Updates, Firmware und Kapazitätstrends.
3-Tier Architekturen
Compute, SAN, Shared Storage und klare Betriebsgrenzen.
Multipath-Architekturen
Fibre Channel, iSCSI, ALUA, multipathd und Failover-Tests.
Proxmox Workshops
Beratung, UI-Durchgang, Betriebspraxis und Team-Enablement.
Proxmox-Cluster sauber planen?
Wir prüfen Anforderungen, Hardware und Betriebsmodell und machen daraus ein Cluster-Design, das im Alltag funktioniert.
Proxmox-Projekt besprechen